Pylon: a foundation library ~ User's guide (Chapter 1) -- contents | previous | next
This chapter introduces the main design principles and the various facilities covered. This is followed by a review of the basic framework of the base data structure components of the library, and then the utility classes. Later chapters will introduce concrete data structures and other classes through their flat short forms.
Pylon is a compact minimalist library with portability as a prime concern. It is essentially a data structure library complemented by a set of often needed general features missing from the standard kernel library (date and time, random numbers, etc). It is thus suitable for use as a support library by other open libraries that can be used with most Eiffel compilers.
While most compiler vendors generally provide data structure libraries, they are often not very open both from a licensing viewpoint -- they are usually licensed with the compiler -- and regarding portability -- they are likely to work well only with the vendor's environment.
Various more open libraries have appeared in recent years but none was found to provide the right blend of portability, compactness, feature set or licensing conditions to the developer of this library.
This library is distributed under a rather liberal licence allowing any use, including modification, redistribution of either source code or binary programs based on it, without conditions apart from keeping the original copyright notice in the library source code. In particular, the source code may be modified and distributed but does not have to be made available to users of binary software.
This section introduces the principles behind the design of the library, mainly portability, minimalism, and reusability.
Portability is an essential feature of this library. It is designed to work with as many Eiffel compilers as possible, and has been tested on most published compilersIt has been ported, as opposed to being portable in principle. Unfortunately, Eiffel code for a data structure library -- using some less portable features of the language like genericity and multiple inheritance more intensely than other libraries -- rarely ports automatically to a new compiler..
Apart from portability at the language level, it uses only standard features from the Standard Kernel library (vintage 1995) maintained by N.I.C.E. (the Non-profit International Consortium for Eiffel) and supported by most current compiler vendors. It also avoids relying on portions of the kernel standard that are not very portable in practice.
As a foundation library for open libraries, it is useful that the library is not heavyweight as it may have to be used concurrently with other similar libraries used in a project -- a single library should not require users to use a particular set of data structures for all the code. A small library is also more approachable and can be mastered more quickly. Finally, a carefully selected minimal set of classes is easier to debug and maintain than a bulky package with many variants of the same constructs.
The library is contained in a single cluster of around 50 classes that can be easily integrated with other software. All classes part of the library are prefixed with P_ to help avoiding name space conflicts.
This policy extends to the choice of supported structures. For instance, it has no singly linked list, because two-way linked list are more general and have no significant disadvantages other one-way lists. When size is important, an arrayed list may be more useful to save space than a singly linked list. A similar policy was followed for single features of a class: a table is not a traversable structure because it can be converted to a list of keys or items, which can then be traversed.
Similarly, features may have been excluded for efficiency reasons. A structure optimised to be searched by key may have no facility for a search by item, which would in any case be slow because of the requirement to iterate linearly over all items of the container. This feature would probably be little used, that is less extensively tested. It is still possible to do item searches in such structure by iterating or searching the corresponding list of items.
The classes aim optimal reusability both for clients and internally: many structures make use of other basic data structures. It does not make use of implementation inheritance generally, on the grounds of portability, validity (implementation inheritance often needs restricted exports, which implies system level validity problems), and to keep straightforward flat-short forms.
The container classes typically use classical algorithms and object-oriented patterns. Originality was not really a concern. Performance should be acceptable but it was not a priority above portability and clean class design. Future versions of the library may be improved in this regard, and user suggestions are welcome.
As already mentioned, the library is a primarily oriented towards data structures. The basic structures are described below, along with the default implementations. There are generally abstract classes describing generic container, so that other implementations are possible.
A simple facility allows saving and retrieving representations of objects into strings, so that they can be stored in external files or sent onto communication channels. It uses a very simple system -- requiring each object to specify its own stored layout -- which has the benefit of being portable across platforms, operating systems and Eiffel compilers.
A few classes implement a simple date and time representation, and make also use of the serialisation facility. Various standard representations are offered.
A simple random number generator is provided.
Beyond the documented core, the library contains a few classes not documented in this manual because they are either evolving or specialised classes used by the library itself for its implementation. For instance, the classes P_FORMAT and P_INTEGER_DECODER provide string manipulation and number parsing services.
The simple class P_PAIR provides a simple way to associate two different types.
A few classes implement (forest) trees but this set is experimental and subject to change. They may become officially part of the library -- or not, as it is not obvious whether trees belong to a minimal library -- and be extended (to support binary trees and the like).
The data structure components follow a classical construction: deferred classes introduce abstract container and manipulation objects, while other classes actually implement the containers. There are normally not many variants of a single type of structure -- because of minimalism and simplicity -- but there is room for expansion by inheriting from the deferred base classes.
The following diagram shows the main public data structure classes and logical inheritance relations. Dotted lines indicate client relationships.
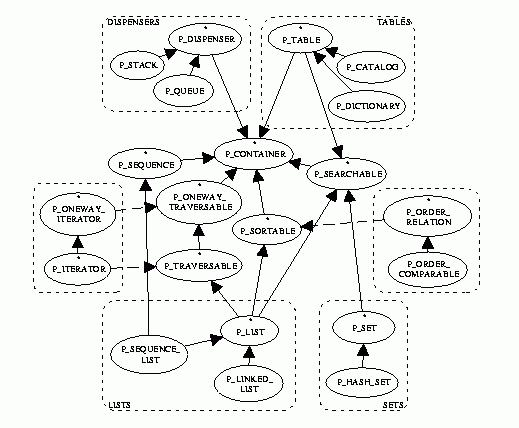
The base class is P_CONTAINER, the root for all container classes. As expected, it takes a generic parameter for the contained type. It introduces the important notion of current item: all containers which are not empty have a current item, accessible through the function (or attribute) item, which can be assumed to have minimal overhead.
Unlike the use of accessor functions like the standard ARRAY's item which takes an index and returns the corresponding item. The notion of current item allows a uniform scheme for all access procedures, like search by key or by value, positioning from an iterator or cursor, which instead of each returning an object, simply change the current position -- a current item means that there is a current position. Other operations like container updates can be done relatively to the current position: for instance, in order to add an item relatively to an existing one in the container, the current position is first changed to the existing item before which the new item is then added.
Apart from the current item, the base container class provides usual features like the values count and is_empty. The boolean flags is_writable and is_readable indicate the current status of the container -- it may be permanent, most containers are always readable for instance. These flags are often use in other routines' contracts.
The procedure reset removes all items from the container, putting it back to a state similar to what it was after creation. Like reset, most container's creation procedures (usually named make) do not take parameters and simply initialise an empty container.
Most direct descendants of P_CONTAINER introduce some abstract types of container, or an abstract facility which can be added to most containers through multiple inheritance. The following sections introduce these abstract classes.
Later on, more concrete -- although still deferred -- classes will be introduced. These define the public interface of some specific type of container. They are descendants of the basic abstract facilities, and their own descendants are the actual implementations. The concrete implementation classes do not usually introduce new public features, apart from their creation procedure (normally a single parameterless procedure named make).
Some containers can be traversed that is each item of the container can be examined and processed in turn, during an iteration other the container's content.
One could think traversal requires an ordered container, so that each iteration processes the items in a fixed order. This is not necessarily the case, though most iterators in this library iterate on ordered structures so the iteration is done following the containers' order.
The problem of iteration using object oriented languages like Eiffel introduce a well-known dilemma between two systems: either the container has a current position and is also a cursor that is the container class also includes features to go `back' and `forth' inside the container, or external objects associated with the container allow iteration on the container objects, thus allowing several iterations to take place at the same time.
The first system, cursor features in the container, is in a way flexible because it allows the container to be changed at any time. For instance, one could go back three items in a list and add an item after the current item, then go forward again. The drawback is that, obviously, there is only one current position at a time, so only one iteration can take place at a time: two components cannot easily concurrently go through the same container, at least not transparently.
The other solution, external iterator objects, suffers from a symmetric problem, that is while one can have several iteration objects at the same time, they cannot generally be used to change the data structure, and more importantly no change to the structure may occur during iteration -- that is if one or more iterators are currently traversing the structure, it becomes read only and cannot be changed. This is necessary because it would be difficult to do something meaningful with an iterator if the structure is changed while it is traversing it: what should happen if the current item one iterator is pointing to is removed for instance, or if an item is added, before or after the iterator's current item -- assuming these notions make sense -- during a live traversal.
While an easy solution would be to offer both solutions and trying to have them cooperate, this library introduces an interesting compromise, which while apparently quite simple proved to be very flexible during actual use.
Like classic iterators, this library's iteration objects make the traversed structures read only, while they are traversing -- that is when they are inside the structure.
The trick is that an iterator can be locked: it is associated with an item in the structure and then the traversal is terminated. A locked iterator is considered to be outside the container, so it is not blocking the whole container anymore. Of course, it is still associated with one item: so this item, but only this item or the item and its dependents in some data structures. For instance if a node in a tree has a locked iterator pointing to it, all its parent nodes will be locked, because removing them would also remove the item in question. is blocked, which typically means that the item cannot be removed. Other changes to the data structure (like adding new items or removing unlocked items) can still be performed.
A locked iterator can be considered as a position inside a container, relative to a particular item. It is possible to start a new iteration from this position by unlocking the blocked iterator. It is possible to terminate the traversal immediately so that some lockable iterators can also be used as a tool to remember positions without performing any actual traversal.
In a word, a structure can only be read if one or more iterator are currently traversing it, but it can be modified (with restrictions) when some iterators are locked -- but not traversing -- on some of the items structures. When no iterators are used, the structure can be modified without restrictions.
Now that the general principle has been presented, lets see how this has been implemented. The two main classes which are intimately related (though only by a client/supplier relationship) are the traversable container and the associated iterators of type P_ITERATOR.
The base traversable container, P_TRAVERSABLE, mainly introduces a function named iterator which returns back a fresh iterator after each calls -- these new iterators are not initialised on any form or traversal and are outside the container. Therefore, just getting an iterator does not block anything in the container.
When some iterators do some actual traversals, the traversed container becomes read only, and the container's boolean flag is_protected is set. This is in turn associated with is_writable from the base container class.
In the case of locked iterators -- which do not contribute to is_protected -- there is the flag has_locked which is set when the container has at least one blocked item and associated iterator. To check if the current item is actually locked, there is the boolean value is_locked. This is a precondition on all procedures in concrete containers that cannot be used on the current item when it is locked (such as removing the item).
Once an iterator has been obtained from a traversable container, actual operations can be performed on this object of base class P_ITERATOR. This class is deferred, the library internally implements concrete iterators for the various traversable data structures. A library client does not create iterators directly, it always gets them from the iterator routine of a traversable structure.
Iterators are typed: they take a generic type being the same as the corresponding traversed container. This means that the iterator has its own item feature and does not need any more contact with the container during the traversal. This approach, as opposed to getting the current item from the container, has several benefits: the iteration is code is more straightforward, iterators can be passed around without direct reference to the underlying data structure, the strong typing helps avoiding errors when several iterators on different types of containers are used, etc.
A few boolean values document the current status of the iterator. The most important is outside which is true when the object is created and becomes false (not outside) when a traversal is performed. It is also false on a blocked iterator, for which is_locked is set.
In addition to these, the iterators also have integer values for use in loop variants, forward_variant and backward_variant. They can be used for simple straightforward loops, obviously they are not usable for sophisticated iterations back and forth inside the container, but most traversals are of the simplest form.
An iterator would be useless without traversal. As it was mentioned earlier, traversals are linear, a live iterator will go through a finite sequence of item -- which cannot be altered as the container is read only during traversal. So, even if the container has no specific ordering for its items, the traversal sequence is ordered.
There are several ways to enter the iterator to begin a traversal: first starts at the beginning of the traversal sequence, last goes to the end of the iterators. These features are also usable on iterators associated with empty containers: in this case, the iterator will remain outside the container.
Another method to enter the iterator is to use synchronize to start the traversal on the associated container's current item, which then must not be empty. The reverse operation is available with live iterators: the procedure synchronize_container changes the container's current item to be the currently traversed item. It is often useful to do this before exiting an iterator, and then performing a change on the container.
To stop the traversal, the procedure stop is normally used. The other case is when the iterator is to be blocked, using lock which associates the iterator with the currently traversed item, as explained earlier, and then terminates the traversal.
The remaining way to start a traversal is to restart a locked iterator from its previous position with the procedure unlock, which also frees the item locked in the container.
The actual traversal is done using the procedures forth for one step forward and back for the same backward.
Now that all features of iterators have been introduced, let see some example of actual iterations. The simplest iteration, on a string container can be expressed like this:
local
it : P_ITERATOR[STRING]
string_cont : P_TRAVERSABLE[STRING]
do
-- Create or retrieve string_cont first.
-- [...]
-- Now iterate on the container.
from
it := string_cont.iterator
it.first
variant it.forward_variant until it.outside loop
process_string(it.item)
it.forth -- next
end
end
This code would also work fine on an empty container (the iterator will be outside after it.first).
If it is necessary to exit the container at some stage, the traversal is stopped. For instance, here is how to find the if an integer container has the value 5:
-- it : P_ITERATOR[INTEGER]
from
it := int_container.iterator
it.first
variant it.forward_variant until it.outside loop
if it.item = 5 then
found_five := true
it.stop
else
it.forth
end
end
Note that the command it.forth needs to be in the else branch because it is not possible to go forward after the traversal has been stopped.
Now lets find the first occurrence of 5 and remove it from the container, assuming that the integer container has a feature remove to remove the current item.
-- Find first occurrence of 5...
from
it := int_container.iterator
it.first
variant it.forward_variant until it.outside loop
if it.item = 5 then
-- sets the container so that this 5 is its current item
it.synchronize_container
it.stop
else
it.forth
end
end
-- ... and remove it if found
if not int_container.is_empty and then int_container.item = 5 then
int_container.remove
end
We may want to add the number 123 after each occurence of 5. The integer container, int_container is now assumed to be some kind of list with a feature insert to add another item before the current one.
-- Add 123 before each occurrence of 5...
from
it := int_container.iterator
it.first
until it.outside loop
if it.item = 5 then
it.synchronize_container -- Locking does not change container position.
it.lock -- Save position and stop traversal.
int_container.insert(123) -- Insert, current item is now `123', before `5'.
it.unlock -- Go back to saved position (5).
end
it.forth -- next
end
For simplicity the presentation above only mentioned the normal, two-way, iterators. They have their one-way counterparts which are useful for some specific structures. The class P_ONEWAY_ITERATOR from which P_ITERATOR inherits is like a normal iterator without the `backward' features. The associated container class is P_ONEWAY_TRAVERSABLE which is the ancestor of P_TRAVERSABLE returning an iterator of the one-way type instead of the two-way type.
Some containers can provide a facility to search an item inside the container. The class P_SEARCHABLE introduces three features for searching: the procedure search does a search, whose result in stored in the boolean value found, true for a successful search and found_count, which is an integer indicating the number of occurences found, if meaningful. The latter is only valid when found is true. After a successful search, the container's current item is set to an item satisfying the search criterion.
The deferred class takes two generic parameters, one for the contained type (the same as the generic type of its P_CONTAINER ancestor, the type of item), and a second one for the search procedure which is the type of its first parameter. It allows to implement various types of search such as searching an item in a list (in this case LIST[G] could inherit from P_SEARCHABLE[G,G]), or a search by key in a table.
The base search class does not mandate any specific search criterion, an actual implementation can typically use object equality (the standard feature is_equal from ANY) or use Eiffel's `=' operator (which means reference equality for reference type and object equality for expanded types like INTEGER).
Typical containers provides access and modification routines relative to the current item, and eventually iterators to manipulate the container, which may also be searchable thanks to the facility just introduced.
Some containers provides an index based access, like access to the individual characters in a standard STRING. This is also similar to an array -- indeed such structures may be implemented with an instance of ARRAY -- with some differences: first, the index is always between 1 and the container's number of item (count from P_CONTAINER, and secondly the structure is normally (but not necessarily) automatically resized.
This kind of structure is called a sequence (sometimes also a vector in other languages or libraries) and is abstracted by the deferred class P_SEQUENCE. The class adds a single feature to the base container, the procedure set_index which sets the position of the current item.
This is in harmony with the uniform general access scheme of this library, and contrasting with the standard library's way of accessing elements of arrays or string.
For instance:
local
string : STRING
array_int : ARRAY[INTEGER]
sequence_int : P_SEQUENCE[INTEGER]
do
-- ... initialise variables ...
-- ELKS access method
io.put_character(string.item(5)) -- Output fifth character of string.
io.put_integer(array_int.item(12)) -- Output integer at position number 12
-- Sequence access
sequence_int.set_index(12)
io.put_integer(sequence_int.item)
end
A container is considered to be ordered when it stores items in sequence, and iterations traverse a container in a predictable order. An example of ordered container can be a simple list or sequence, an example of container which is not sorted can be a hash table: if iteration is available the order is not predictable and can change when the hash table is resized.
An ordered container can be but is not necessarily sorted, a priority queue or a binary tree are instances of ordered containers: the items are always sorted and iterations occur in sorting order.
It may be useful to sort on demand the contents of a container which is ordered but not sorted: for instance sorting a list according to various comparison criteria.
These containers can inherit from the class P_SORTABLE. This provides the interface to sort a container according to an order relation between items. Unlike some classic designs based on constrained genericity and the kernel's class COMPARABLE, this facility can use arbitrary ordering relations on the same container. It is possible to order a list of messages by subject or author or date among other things.
In order to sort such a container, the order relation is set using set_order, which is a procedure taking a descendant of the class P_ORDER_RELATION. This class contains a single deferred function, ordered which takes two consecutive items and returns a boolean value -- true if they are ordered.
For instance, assuming a message class (EMAIL_MESSAGE) with string attributes subject and author, the following order relations could be used This example uses STRING's `<' operator for string comparisons, which is not necessarily the most appropriate being limited to ASCII sorting, but it is well known and suffices for the sake of an example.:
class ORDER_SUBJECT
inherit P_ORDER_RELATION[EMAIL_MESSAGE]
feature
ordered(first,second : EMAIL_MESSAGE) is
do
Result := first.subject < second.subject
end
end
class ORDER_AUTHOR
inherit P_ORDER_RELATION[EMAIL_MESSAGE]
feature
ordered(first,second : EMAIL_MESSAGE) is
do
Result := first.author < second.author
end
end
After the order relation has been set, the container can be sorted using the procedure sort and the current ordering state can be checked with is_ordered. The order relation is persistent until it is explicitly changed -- it remains the same even when the container is reset.
So, in the case of the email message, sorting would be performed like this:
local
list_message : P_SORTABLE[EMAIL_MESSAGE]
by_subject : ORDER_SUBJECT
by_author : ORDER_AUTHOR
do
-- ... initialise objects ..
-- Sort email list by subject
!!by_subject
list_message.set_order(by_subject))
list_message.sort
-- Sort email list by author
!!by_author
list_message.set_order(by_author)
list_message.sort
end
While the order relation scheme is flexible, it is also quite often remains meaningful to order items which inherit from COMPARABLE using the standard relation. In this case the library provides the class P_ORDER_COMPARABLE which links ordered with COMPARABLE's `<' operator. This class still takes a generic parameter which must conform to the container's generic type because of the type checking rulesThe container's set_order takes a P_ORDER_RELATION[G] parameter, with G being the container's generic parameter, so a say INTEGER container cannot accept set_order with a parameter conforming only to P_ORDER_RELATION[COMPARABLE] -- the parameter need conform to P_ORDER_RELATION[INTEGER]..
A list of integers could be sorted like this:
local
list_integer : P_SORTABLE[INTEGER]
comparable_order : P_ORDER_COMPARABLE[INTEGER]
do
-- Initialise variables ...
-- Sort
!!comparable_order
list_integer.set_order(comparable_order)
list_integer.sort
end
All basic abstract containers have now been reviewed, the remaining deferred classes are more complete containers.
The first one is very simple. Dispensers are containers to which new items can be added and existing items can be removed one at a time. The client does not access the internal structure. Typical application are stacks and queues. In the case of a FIFO queue, or stack, items are put on the stack and retrieved in first-in-first-out order.
The class P_DISPENSER inherits from the basic container, and adds the procedures add to add a new item and remove to remove the item at the top of the dispenser -- the item itself is the container's current item as usual. This may look unusual to readers used to a `push' and `pop' system often used in other languages. The reason for this approach is, first, consistency with the naming of the routines in other containers and, secondly, the requirement of Eiffel-style code not to use functions with side-effects.
Another basic data structure is the list, which is a simple ordered (but not sorted) sequence of items.
The class P_LIST inherits from several basic facilities: a list is traversable (P_TRAVERSABLE), sortable (P_SORTABLE) and searchable (P_SEARCHABLE).
There are two ways to search a list, so there is no procedure called search but two: value_searchfor search by value using is_equal to compare items, and equality_search for use of the `=' operator.
In addition to the features inherited from the ancestor classes, a list has features to modify it: add is used to append an item at the end of a list; insert to insert one before the current item Insertions are done before rather than after the current item, because it is needed to have a feature to add at the head of the list -- insert before the first item -- while adding at the end of the list is performed with add.; and remove to delete the current item from the list.
While the class redefines copy and is_equal from ANY, these functions are useful mainly when both list object are of the same dynamic type. The procedure from_list allows to initialise a list from another one, from_list takes a P_LIST parameter. The equality between lists of possibly different dynamic type can be checked using is_equal_list -- the standard is_equal requires the dynamic types to be the same.
It is also possible to initialise a list from a standard array using from_array, or from another traversable container with from_iterable which takes a parameter of type P_ITERATOR. These routines have counterparts for appending elements to an existing list, append to merge with another list, and append_iterable for a traversable structure.
Finally, the content of a list can be used to fill a standard ARRAY thanks to the function to_array.
A set is a data structure which can contain at most one instance of a given object. For unicity to make sense, it is necessary to define equality between two objects, for which this library uses the standard relation is_equal from ANY.
This works well with both expanded types and reference types. For instance, a set of INTEGER cannot have the same number twice. For reference types, it is often useful to redefine is_equal to have a clearly defined notion of unicity.
As a client often needs to know quickly whether an object is in the set, and it often has to be checked before adding a new item, this operation must be performed quickly. It would be possible to use the search function of a list to implement a set, but that would be inefficient. An essential characteristic of sets is that a search is performed quickly, usually in constant time (amortised).
The deferred class P_SET inherits from P_SEARCHABLE -- whose features search and found can be used to check if the set has the object. An additional function which does not change the state (current item), has, returns a boolean value and can be used for example in preconditions.
The set can be changed using the procedures add, and remove -- the latter applies to the current item, after a search for example.
A set is not traversable -- fast search is the essential feature -- so a function to_list returns a list corresponding to the content of the set. The order of the items in this list is implementation dependent.
It is very often useful to store objects which are indexed and retrieved another type of object, the key. Tables are the generic structure handling this kind of container, thanks to the class P_TABLE.
The class, and effective descendants, take two generic types: the first is the contained type -- item is of this type --.and the second is the key type. Like the items in a set, the keys in a table are compared using is_equal.
The container is searchable with key_search (renamed from P_SEARCHABLE) which has a parameter of the key type. In addition to the current item, there is a corresponding current key. Depending ot the kind of table, one or more items may be associated with a given key, something that descendants will decide, through the function is_key_writable which allows to check if another item can be associated to the specified key and added to the container.
The modification procedures follow the now familiar pattern: add takes an item and associated key; replace changes the current item, which is associated with the same key as its predecessor; and remove deletes the current item, and the key if no other item is associated with it.
Pylon provides a small set of general classes missing from the standard kernel to complement the data structure classes. The following diagram shows these classes.
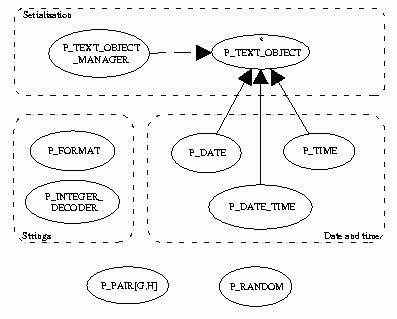
It is sometimes useful to have a representation of an object that may be stored in a file or in a configuration management facility; or to send objects over communication devices. One way to implement this is to serialise objects to text strings which can then be manipulated by any third party class which can operate on strings or byte streams.
A class that can be serialised using Pylon's scheme inherits from P_TEXT_OBJECT which adds the public features from_string and to_string to the object.
Some serialisation systems are supported by compiler vendors. They often make use of the compiler's intrinsic knowledge of object layout to automate the process. While this approach is apparently simple for the users, there are several caveats: the serialisation process is generally compiler dependent, indeed in some cases platform dependent; it is also sensitive to implementation changes such as adding or removing or renaming the attributes of an object.
Moreover typical systems usually do a snapshot of the runtime objects and save them `as is' which is not necessarily what is needed. For instance, when saving a list of objects, it makes sense to use a simple technique like a text file with one record per line or the list or table feature of an external database -- it is not very appropriate to do a snapshot of a particular Eiffel list structure (with the node objects of a linked list for instance) lessening the reusability potential should the runtime structure be changed or updated).
Finally, these systems do not typically handle version management issues and do not allow different versions of a system to retrieve saved objects after evolution of either the implementation or the actual content of the object.
The facility provided by P_TEXT_OBJECT is independent of the compiler, platform and implementations details, and a versioning system can be easily implemented by the user. Of course, as this is a very simple system, this versatility has a cost: the schema for each saved object must be specified explicitly by the programmer.
The procedures object_to_string and string_to_object are deferred in P_TEXT_OBJECT and must be effected by descendants. They are called by the library when the client uses the string functions; that's why they are exported to the classification class PUBLIC_NONE. Both these procedures have a single parameter, of type P_TEXT_OBJECT_MANAGER, which provides an object similar to the kernel's input/output streams (e.g. io from GENERAL).
When to_string is used by a client of a P_TEXT_OBJECT descendant, the procedure object_to_string is called with an initialised text object manager. The effected procedure then `pushes' base types (BOOLEAN, CHARACTER, STRING, INTEGER, REAL, DOUBLE) on the object stream using typical procedures such as put_boolean, put_character, put_integer, etc.
In case it is needed to add a non-basic type to the stream, it is possible to add either the embedded object's own attributes, or -- possibly recursively -- make this object serialisable and then use put_object. It would be of course possible to use the generic put_string for any P_TEXT_OBJECT descendant, but put_object is more efficient and convenient, because it knows the string is the result of a serialisation so it can make some assumptions on its syntax and avoid an inefficient encoding.
The procedure string_to_object mirrors the previous one for the opposite operation: retrieving an object from an encoded string (through P_TEXT_OBJECT's from_string, which could also be a creation procedure of descendants).
The client has an added constraint: the stream may have been corrupted, or for some reason may not contain the required values. To check this, P_TEXT_OBJECT_MANAGER has a boolean value called in_success which is set after each retrieval operation. Retrievals themselves are done using classical procedure/value pairs like get_integer andlast_integer or get_string and last_string.
It is not required to check in_success after each request, if the correct value is not found, the default value for the given type is returned. An implementation can thus check that the retrieval was successful at the end of the retrieval routine for instance.
Unlike the others that use a separate value for the result, the procedure get_object takes a parameter of the corresponding base type, which is changed using its procedure from_string, because it is not possible to create dynamically an object of the proper typeA creation procedure cannot be dynamically dispatched, the static type must be known in order to create a new object..
Lets implement the text object procedure for a simple BANK_ACCOUNT object which has simple attributes that need to be stored.
class BANK_ACCOUNT inherit P_TEXT_OBJECT
-- (...)
feature -- Attributes
owner_name : STRING
balance : INTEGER
overdraft_allowed : BOOLEAN
feature { PUBLIC_NONE }
object_to_string(tm : P_TEXT_OBJECT_MANAGER) is
do
tm.put_string(owner_name)
tm.put_integer(balance)
tm.put_boolean(overdraft_allowed)
end
string_to_object(tm : P_TEXT_OBJECT_MANAGER) is
do
tm.get_string
owner_name := tm.last_string
tm.get_integer
balance := tm.last_integer
tm.get_boolean
overdraft_allowed := tm.last_boolean
if not tm.in_success then -- Retrieval failed
reset
end
end
-- (Other features omitted...)
end
Note that the success status is checked only at the end. It could also be checked after each retrieval operation.
The object could use other objects. For example, the account owner could be an object ACCOUNT_HOLDER instead of a string. This class should then be a descendant of P_TEXT_OBJECT, and the features put_object and get_object would be used instead of the string functions.
It is not necessary to put every attributes in the serialised version -- or any real attributes in fact. For example, various coordinates objects could always be serialised as cartesian coordinates, even for an object using polar coordinates. It is useful for the saved version to be more abstract than runtime implementations, so that porting and evolution are easier.
The handling of stored objects produced by various versions of a a same project is an important portability issue. A distributed system may involve using concurrently several versions of the client software. A new version of a program may have to read configuration information saved by a previous release of the program.
This library has no built-in scheme for handling version control because it can be implemented very easily using the existing facilities. A simple way to handle object versions, is to put as the first value on a stream an integer (or a string or whatever) representing a version number.
Back to the bank account example, lets assume that the previously presented example has evolved to use a bank customer object instead of a string for the owner name. For this to be possible, the developer must have anticipated evolution, and used a version number in the original version. So, the serialisation procedures looked like:
object_to_string(tm : P_TEXT_OBJECT_MANAGER) is
do
tm.put_integer(1) -- Version number
tm.put_string(owner_name)
tm.put_integer(balance)
tm.put_boolean(overdraft_allowed)
end
string_to_object(tm : P_TEXT_OBJECT_MANAGER) is
local
version : INTEGER
do
tm.get_integer
version := tm.last_integer
tm.get_string
owner_name := tm.last_string
tm.get_integer
balance := tm.last_integer
tm.get_boolean
overdraft_allowed := tm.last_boolean
if not tm.in_success or else version /= 1 then -- Retrieval failed
reset
end
end
The new version of the object can read the previous one:
class BANK_ACCOUNT inherit P_TEXT_OBJECT
feature -- Attributes
owner : BANK_CUSTOMER -- Another descendant of P_TEXT_OBJECT
balance : INTEGER
overdraft_allowed : BOOLEAN
feature { PUBLIC_NONE }
object_to_string(tm : P_TEXT_OBJECT_MANAGER) is
do
tm.put_integer(2) -- This is version #2
tm.put_object(owner)
tm.put_integer(balance)
tm.put_boolean(overdraft_allowed)
end
string_to_object(tm : P_TEXT_OBJECT_MANAGER) is
local
version : INTEGER
do
tm.get_integer
version := tm.last_integer
inspect version
when 1 then
tm.get_string
!!owner.make_from_name(tm.last_string)
when 2 then
!!owner.make -- new owner object to be updated by `from_string'
tm.get_object(owner)
else -- unknown result handled later
end
tm.get_integer
balance := tm.last_integer
tm.get_boolean
overdraft_allowed := tm.last_boolean
if not tm.in_success or else (version < 1 or version > 2) then
reset -- default object in case of error
end
end
-- Other features omitted...
end
A user of the text object class does not need to know about the low-level encoding used to put the values into a text string. To be exhaustive, this section documents the encoding scheme used. It is not normally useful to manipulate it directly, but can be useful for debugging or implementing utilities manipulating this format.
Some properties of the encoded strings are useful to know to be able to process them: strings are made of ascii characters that do not include control characters (below the character code 32 in ascii). It means that for instance a list of encoded objects may be stored as lines of a text file.
Each attribute of an object is stored as the following substring:
'(' <type> ':' <content> ')'
The <type> tag is a short ascii tag which indicates the tag corresponding to the type of attribute, such as `INT' for integers. This permits the introduction of some typing into the text stream -- though this is limited: it indicates for instance that there is an integer, not what this integer is used for. This can be of some use to check the integrity of a stream, but it is more importantly used for the decoder to properly process the following data which is stored in the <content> field.
The content must fulfil the same requirements as the strings themselves. In addition, it must be possible to find the end of the content data, so the content field must have balanced parenthesis. Parenthesis could have been encoded like control characters but balanced parenthesis allow a more efficient encoding of recursive objects (from put_object in P_TEXT_OBJECT_MANAGER).
The encoding themselves are trivial decimal representations for numbers (types `INT', `REAL', `DBL'). Booleans values, `BOOL', are either ``true'' or ``false'' (in ascii). Characters are not changed unless they are control characters, in which case they are encoded as their hexadecimal integer code prepended by the encoding character `%'.
This encoding character is also used for encoding control characters, including the encoding character itself, for string values -- the tag is `STR'. Inside strings, the encoding character is placed before and after the hexadecimal character code, to allow variable lenght character codes.
The object encoding (`OBJ' tag) is the result of P_TEXT_OBJECT's function to_string left untouched, because it cannot contain control characters or unbalanced parenthesis.
In conclusion, here is an implementation of object_to_string (using constants) and the corresponding encoded string:
object_to_string(tm : P_TEXT_OBJECT) is
do
tm.put_boolean(true)
tm.put_integer(1887)
tm.put_real(10.23)
tm.put_string("The encoding character is: %%")
end
gives:
``(BOOL:true)(INT:1887)(REAL:10.23000)(STR:The encoding character is: %25%)''
The date and time classes are straightforward. The separate date and time classes do not inherit from each other. The combined date and time class uses date and time attributes instead of using multiple inheritance from the date and time classes. This is simpler and more portable and provides access to all the features of the component objects.
All these classes inherit from COMPARABLE and HASHABLE so that they can be stored and ordered in a standard way. They also all inherit from P_TEXT_OBJECT and can thus be stored as text strings.
These classes do not provide features to initialise them to the current time, as this is a function better provided by operating system specific libraries, which can of course use these classes.
The date class, P_DATE has the obvious integer attributes year, month and day with their corresponding access features -- set_year and consorts. The feature set allow to change all three parameters at once.
The boolean value is_valid is true when the date is an existing day, e.g. not the 31st of April. The single number access functions just test minimal validity (such as a day being between 1 and 31), but set has a precondition using the boolean function is_valid_date which allows tests without changing the current object.
The values is_leap_year, day_of_week and day_of_year provide information that can be computed from a valid date.
The remaining features are functions that return a string containing various text representation of the date. The formats available are ISO 8601 format (to_iso, e.g. "18870726") and expanded ISO format (to_iso_long, "1887-07-26") Western readers may find this format slightly unusual and another product of an out of touch standard body, but it is actually the most widely used format on Earth, being the standard in China and most other Asian countries (and Scandinavia in Europe). It is also the most logical -- starting with the most significant number, like time of the day or decimal numbers. It is also understood easily by everyone and is not as ambiguous as the European and American formats. and the old fashioned American and European formats (to_european and to_american) and finally to_rfc for the canonical RFC-822 (Internet email) format. The standard feature out is mapped to to_iso.
Like its date relative, the time class P_TIME has integer values for the time data, hour, minute and second and corresponding access features -- set for all parameters and set_hour and others for changing one value at a time. The hour is normally in 24 hour format (between 0 and 23 included), but the function hour_12 returns the corresponding 12 hour format value (1-12), in association with boolean values is_am and is_pm.
There are two string representations, from to_iso (233055) and to_rfc (23:30:55). The standard out is the same as to_iso.
When both the date and time are needed in conjunction, the class P_DATE_TIME provides a combined object for date and time with the time zone optionally specified.
The class has attributes date and time of the corresponding types. It is possible to change the date and time using set_date and set_time, or set for both. All these procedures takes integer values, like the setting features of the attributes which can also be used.
If no time zone information is set, the date is supposed to be local and is_local is true. The timezone bias information -- the difference from UTC (also knows as GMT) -- can be changed using set_timezone_bias taking the difference in minutes. This value can be retrieved from timezone_bias, and the boolean is_utc indicates UTC time -- when the bias is zero. UTC bias has to be specified like any other, because the default is local time, not UTC.
The string functions to_iso, to_iso_long and to_rfc return a textual representation of the date and time made from the corresponding date and time representations, to which the time zone information is appended when it is defined.
Some applications need random numbers and the standard kernel libraries do not provide this. The class P_RANDOM is a simple pseudo-random number generator.
The generator is initialised by the seed, an integer number used to start the pseudo-random sequence (which is the same every time the generator is run with the same seed). The seed is the parameter of the creator procedure, make. An existing object can be initialised again using the same procedure under the name reset. Values like a clock or system timer or a counter whose value is practically unpredictable are good candidates for a seed when reasonably random results are required.
Once the generator has been started, new random numbers are obtained by calling the procedure get_number whose arguments define a positive integer range. The value is then available from the attribute last_numberA function returning the number directly would go against the Eiffel principle which states, rightly, that functions should not have side effects..
A few classes don't fit in any category and so have been grouped in this section.
First, P_PAIR is a trivial class to associate two objects. It has two generic parameters with their corresponding attributes and access methods, one and set_one for the first one, and two and set_two for the other.
The class P_INTEGER_DECODER is a simple class used to decode and encode integers to strings, in any base supported by the encoding table which associates numbers to individual character. The default is `0' to `9' to their corresponding decimal number and `a' ... 'z' (case insensitive) associated with 10 to 35, so the default maximum base is 36. 10 and 16 are likely to be popular choices. The base is the parameter of the creation procedure, make.
Individual digits can be converted to characters and conversely using char_to_int and int_to_char. These functions have strict preconditions, like is_digit, which must be checked for data that has not been validated.
At the string level, from_string (which is a procedure, the result is the integer attribute value) and value_to_string operate on single strings.
The class can also be used as a state machine, which can be convenient when operating on a stream -- there is no need to create a temporary string. The result is stored in value. The machine is initialised using reset. Every new digit is fed to the state machine -- from the most to the least significant as expected -- using extend which takes a character parameter.